
First, let’s cover PCollections and Elements.
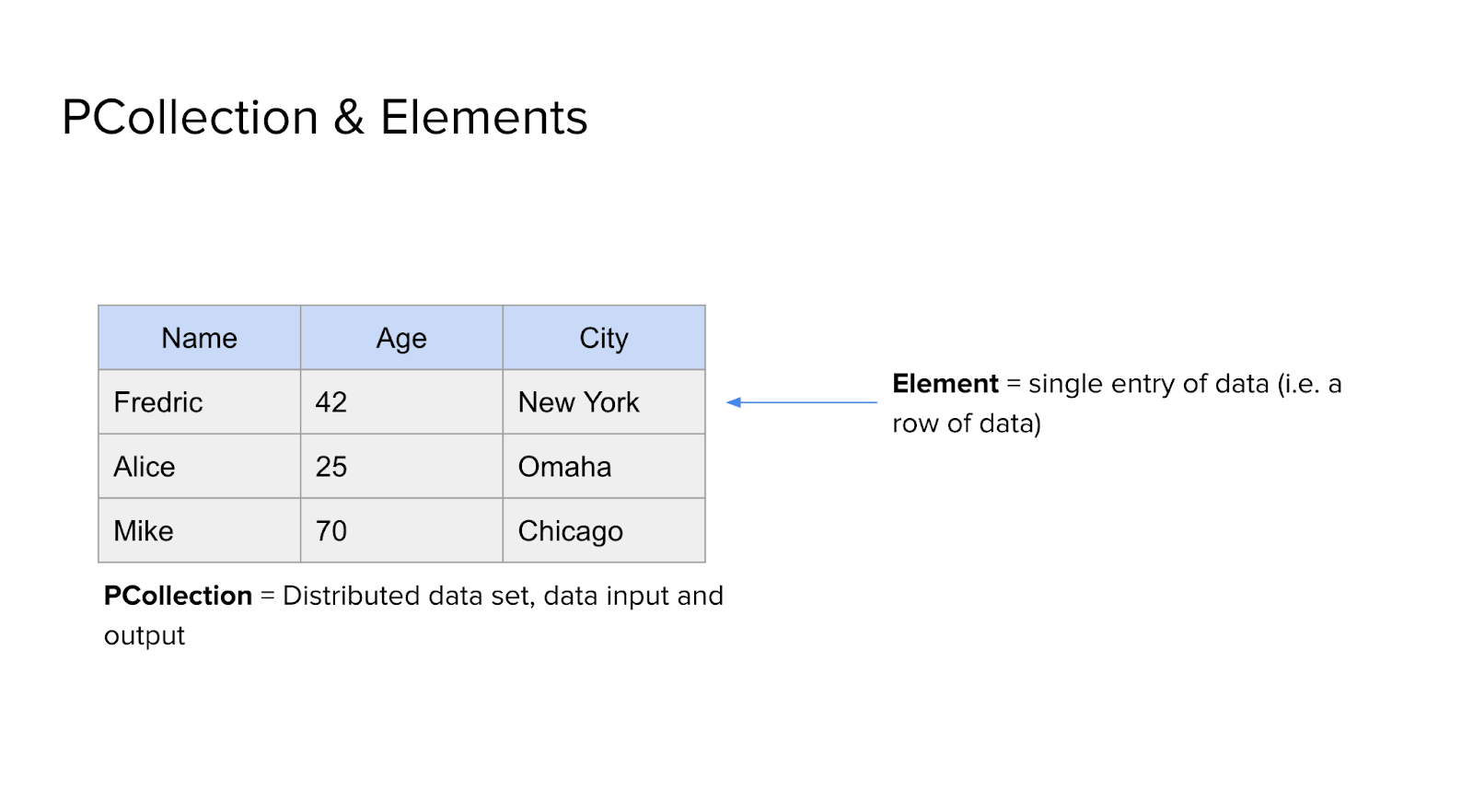
A PCollection is a distributed dataset. It’s essential the object that you put into your pipeline, and what you get out of the pipeline. In this case, we have three attributes - name, age, and city - in our PCollection.
An element, as defined here, is a single entry of data. In our example, each row (e.g., Fredric, Alice, Mike) represents one element, and each element has three attributes: Name, Age, and City.
So this is a simple table with a collection of data elements, each row being an individual element in the PCollection.
It’s important to understand that PCollections are not stored as one big, centralized dataset like we usually imagine when we think of tables or databases. Instead, they are spread across multiple nodes or machines.
In this visual example, we have a PCollection with 5 rows, and the rows get distributed across the worker nodes in the cluster.
Each worker node, as you can see on the right, is responsible for handling a subset of the overall dataset. In this case, our example PCollection, visualized on the left, has been broken into different parts.
The elements within the PCollection are divided across these worker nodes, allowing them to process data independently. For example, one machine might be handling the first few rows of data, while another handles different rows.
This allows for greater scalability, as you can add more worker nodes to handle more data. It also ensures that processing can happen in parallel, making the whole operation much faster.
The important takeaway here is that PCollections are inherently distributed by design, ensuring that large-scale data processing can be done efficiently over many machines.

Next, we introduce PTransform, which is a key general concept in both Apache Beam and Dataflow. A transform is a general term for any processing operation applied to data. In the context of Dataflow, PTransform stands for a "Pipeline Transform," which takes data, perhaps messy or unfiltered in some way, processes it, and outputs a new data collection, usually clean or aggregated data.
Here on the left, we have messy data, represented by dots in various colors, flowing into the PTransform, which is the core processing step. After the PTransform, the data is organized and clean, as shown on the right side, ready to be used for analysis or further storage.
There are several types of PTransforms available, each serving a different function for handling and processing data. We’ll be covering the main types in the upcoming slides, focusing on those that are most relevant for the exam.

In this slide, we're looking at two key concepts used in Dataflow: ParDo and DoFn.
ParDo is a type of transformation that gets applied to each element in a PCollection. It's particularly useful for filtering or extracting elements from large datasets. For example, if you need to remove invalid data or select only certain elements based on a condition, you would use ParDo to achieve that.
DoFn is the custom logic that gets applied to each element as part of the ParDo transformation. It's essentially a function you write to define how each element should be processed. Whether you're validating, filtering, or modifying data, the DoFn dictates what happens to each element in the dataset.
To make this concrete, let’s walk through a diagram below:
On the left side, we have a PCollection of customer records. Each row in this table is a single element—representing a different customer. In this example, our task is to filter out inactive customers.
The ParDo operation is represented by the funnel in the middle of the slide. It is what filters out inactive customers. As the PCollection flows through, the DoFn applies a custom logic that checks whether a customer is active or not. The DoFn is that custom logic.
As a result, inactive customers are removed, and the PCollection that exits the funnel on the right side now only contains active customers.
This process illustrates how ParDo and DoFn can be used to refine datasets by applying custom transformation logic at the element level.
.png)


