
Dataplex is a relatively recent addition to the Google Cloud Platform (GCP) ecosystem and represents a strategic shift in how cloud-native data management is envisioned.
As organizations increasingly operate across a diverse array of data environments - ranging from data lakes to warehouses to operational databases - GCP has sought to simplify and unify the overall data landscape. Dataplex plays a critical role in this evolution by introducing a governance layer that spans decentralized storage environments. In doing so, it enables organizations to maintain centralized control while granting teams the autonomy to manage their own data products. This dual structure mirrors the emerging architectural principle known as the data mesh.
To appreciate what Dataplex offers, one must first understand the conceptual framework of the data mesh. Consider a typical enterprise composed of several functional domains such as Marketing, Finance, Product, Sales, and Analytics.
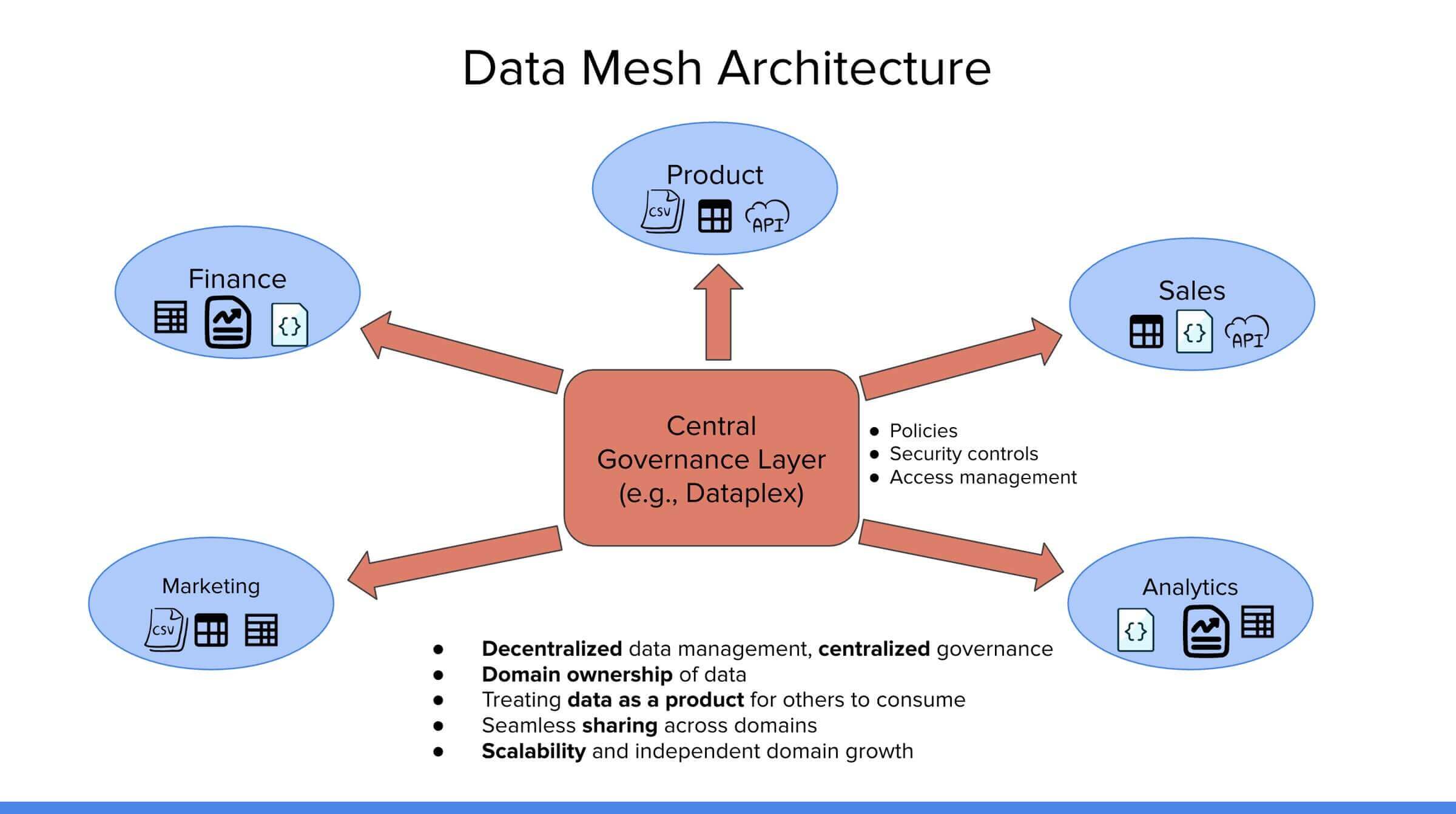 Standard example of data mesh architecture. Dataplex is the central governance layer in this case.
Standard example of data mesh architecture. Dataplex is the central governance layer in this case.Each of these domains produces and maintains its own data products, which may include structured tables, CSV files, JSON documents, or APIs.
These assets are tailored to meet domain-specific requirements and are governed locally. This localized control and stewardship is what defines the decentralized nature of a data mesh. Each team determines the structure, quality, and accessibility of its data while still retaining the responsibility to make it consumable by others within the organization.
While data ownership in a mesh architecture is decentralized, governance is intentionally centralized.
This central governance layer enforces policies, access controls, and security standards that apply uniformly across all domains. This ensures that although teams maintain autonomy over their datasets, organizational compliance, data security, and interoperability remain intact. The result is a system that encourages innovation at the domain level without sacrificing consistency or control at the organizational level.
Several principles define the effectiveness of this model:
This architectural model sets the stage for understanding Dataplex, which operationalizes these principles within GCP.
Dataplex is described as an intelligent data fabric because it integrates the management of data across diverse environments into a single framework. It provides a unified control plane for overseeing storage systems like BigQuery, Cloud Storage, and more, thereby reducing fragmentation and complexity.
The platform offers three essential capabilities that reflect its strategic purpose.
First, it enables unified data management by allowing users to handle datasets across various storage types from a central interface.
Second, it automates the data lifecycle, streamlining tasks such as retention enforcement, archival, and deletion.
Third, it includes integrated analytics capabilities, allowing users to query and visualize data without having to move it into separate analysis platforms.
Beyond these functional aspects, it also includes robust governance and metadata tools.
Features such as data cataloging, lineage tracking, and quality monitoring are built in, reinforcing its role as a kind of glue between domain ownership and enterprise governance.
The overarching goal is to reduce the operational burden on individual teams while enhancing visibility and control for data stewards.
In contrast, traditional data architectures typically centralized both storage and governance, placing all data into a monolithic warehouse managed by a single team.
Dataplex has started to make its way into the GCP certifications, most prominently the Google Cloud Professional Data Engineer certification.
For those preparing for the Professional Data Engineer exam, the key to understanding Dataplex lies in its conceptual alignment.
Whenever the exam refers to decentralized data management, centralized data governance, or the idea of a data mesh, Dataplex is probably the solution.
While the tool itself may still be in the early stages of broad adoption, its inclusion in the exam signals GCP's intention to promote forward-looking architectural models that can scale effectively with modern enterprise needs.

