
Understanding Google Cloud Platform's (GCP) Compute Engine Managed Instance Groups (MIGs) and their reliability features is essential knowledge for the Professional Cloud Architect exam (take my course here).
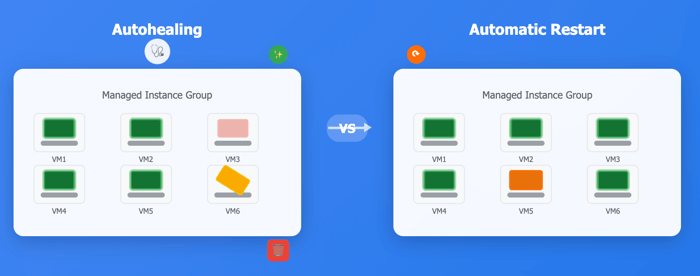
Two important reliability features are autohealing and automatic restart, which help maintain availability and reduce downtime.
Let's take a look at how.
Understanding Autohealing in Compute Engine MIGs
Autohealing automatically recreates unhealthy virtual machines in your Compute Engine MIG when they cannot be easily fixed.
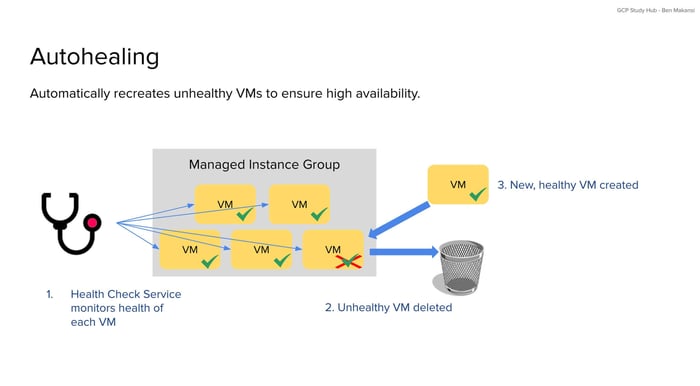
The autohealing process works through a detailed sequence of steps:
Step 1: Continuous Health Monitoring
GCP's health check service runs continuous assessments of each Compute Engine VM in the instance group. These health checks operate on a configured schedule, typically every 10 seconds by default, though this can be customized. The service can monitor various indicators including HTTP response codes from web applications, TCP connection success, or custom application-specific endpoints that signal proper operation.
Step 2: Health Check Evaluation
When a VM receives a health check request, it must respond within a specified timeout period (default is 5 seconds). The health check service evaluates the response against predefined criteria. For HTTP checks, this might mean receiving a 200 status code. For TCP checks, it means successfully establishing a connection. If the VM fails to respond or returns an error, the health check marks that attempt as failed.
Step 3: Failure Threshold Assessment
A single failed health check does not immediately trigger autohealing. Instead, the system tracks consecutive failures over time. Only when the number of consecutive failures exceeds a configured threshold (recommended to be 3 or more) does the system mark the VM as unhealthy. This prevents temporary network issues or brief application hiccups from causing unnecessary VM replacement.
Step 4: Initial Delay Consideration
During a VM's initial delay period (configurable between 0 and 3600 seconds, with a default of 300 seconds), the MIG ignores unsuccessful health checks because the VM might still be in the startup process. This prevents premature recreation of VMs that are simply taking time to initialize their applications.
Step 5: VM Deletion
Once a VM is definitively marked as unhealthy and the initial delay period has passed, the autohealing mechanism initiates deletion. The system stops the VM, removes it from the load balancer rotation, and permanently deletes the instance.
Step 6: Replacement VM Creation
After deleting the unhealthy VM, autohealing immediately begins creating a replacement. The new VM is provisioned using the exact instance template defined for the MIG, ensuring it has the same machine type, disk configuration, network settings, and startup scripts as the original.
Step 7: VM Initialization and Integration
The new Compute Engine VM boots up, runs its startup scripts, and begins accepting traffic. Once the replacement VM passes its initial health checks, it becomes fully integrated into the instance group and begins receiving traffic from the load balancer.
Important note: After autohealing setup is complete, it can take up to 10 minutes before autohealing begins monitoring VMs in the group.
Automatic Restart: Quick Recovery for Temporary Failures
Automatic restart addresses temporary failures through simple reboots rather than complete VM replacement. This GCP feature works on both standalone Compute Engine VMs and VMs within MIGs.
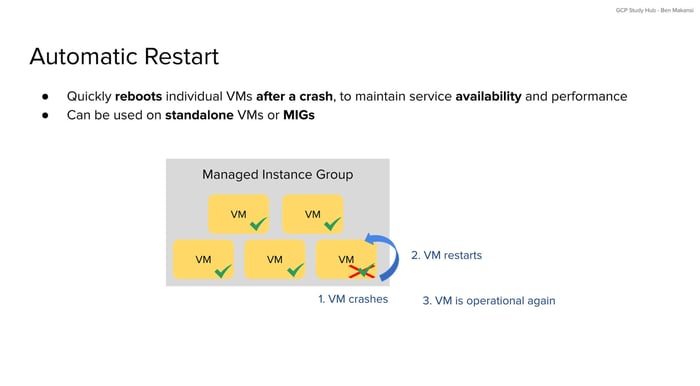
The automatic restart process follows these detailed steps:
Step 1: Crash Detection
GCP's monitoring systems continuously observe the state of Compute Engine VMs. When a VM crashes due to kernel panic, hardware failure, or other system-level issues, the hypervisor layer immediately detects the failure. This detection happens within seconds of the actual crash event.
Step 2: Error Detection Timeout
The system waits for a configurable error detection timeout (between 90 and 330 seconds, with a default of 5 minutes and 30 seconds) before determining that the instance is truly unresponsive and needs to be restarted.
Step 3: Restart Decision Logic
Upon detecting a crash and completing the error detection timeout, the system evaluates whether automatic restart is enabled for the affected VM. If enabled, it immediately begins the restart process rather than waiting for manual intervention. The system also checks for any restart policies that might limit the frequency of automatic restarts to prevent restart loops.
Step 4: VM State Preservation
Before initiating the restart, the system attempts to preserve any persistent disk data and network configurations. Persistent disks remain attached and unchanged, while ephemeral local SSDs lose their data as expected. Network IP addresses and firewall rules remain in place.
Step 5: Hardware Reallocation
The system allocates new underlying hardware resources for the VM if the original hardware experienced a failure. This might involve moving the VM to a different physical host within the same zone while maintaining the same VM configuration and attached persistent disks.
Step 6: Boot Process Execution
The VM begins its normal boot sequence, loading the operating system, running startup scripts, and initializing applications. This process typically takes the same amount of time as a normal VM startup, usually ranging from 30 seconds to a few minutes depending on the VM configuration and application complexity.
Step 7: Service Restoration
Once the VM completes its boot process and applications start successfully, it resumes normal operations. If the VM is part of a MIG with a load balancer, it begins receiving health checks and eventually returns to the traffic rotation once it passes those checks.
When to Use Each Feature
The decision depends on the nature of the failure. Automatic restart works well for temporary issues like system crashes that can be resolved through rebooting, where the underlying VM configuration remains sound. Autohealing addresses persistent problems where the VM cannot be restored through simple restart procedures and requires complete replacement.
A reasonable approach combines both features to handle quick-recovery scenarios and more serious failures requiring complete VM replacement. Together, these features reduce operational overhead by automating failure response while maintaining availability standards.
Conclusion
Understanding autohealing and automatic restart concepts is important for success on the Professional Cloud Architect exam, as these features represent fundamental reliability patterns in GCP.
If you'd like to study for the exam, check out my Professional Cloud Architect course.
By learning when and how to implement these Compute Engine MIG capabilities, cloud architects can design solutions that automatically maintain service availability even when individual components fail.