
Understanding Google Compute Engine (GCE) location options is essential knowledge for the Professional Cloud Architect exam. The decision of where to place your Compute Engine virtual machines (VMs) involves selecting the right region and zone combination, which becomes permanent once set and can impact your application's performance, costs, and reliability.
If you would like to learn more about Compute Engine and prepare for the Professional Cloud Architect certification exam, you can do so using my course.
VM Location Basics
When creating a VM instance, one of the first decisions involves selecting the geographic location through region and zone selection. Regions represent broad geographic areas such as "us-central1" (Iowa) or "europe-west1" (Belgium), while zones are specific data center locations within those regions, like "us-central1-a" or "us-central1-b."
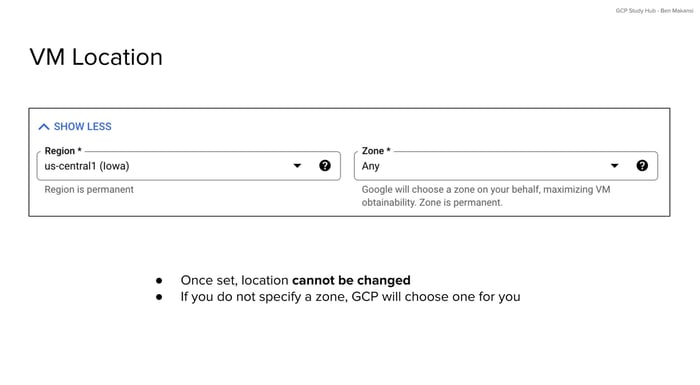
The location decision carries permanent consequences. Once you create a VM instance in a specific region and zone, you cannot change this location. The instance remains tied to that geographic location for its entire lifecycle. This makes the initial location choice worth considering carefully for long-term infrastructure planning.
GCP offers some flexibility through automatic zone selection. If you don't specify a zone during VM instance creation, Google Cloud will choose one for you within your selected region. This automatic selection can help with instance availability when certain zones experience resource constraints or capacity limitations.
Strategic Location Considerations
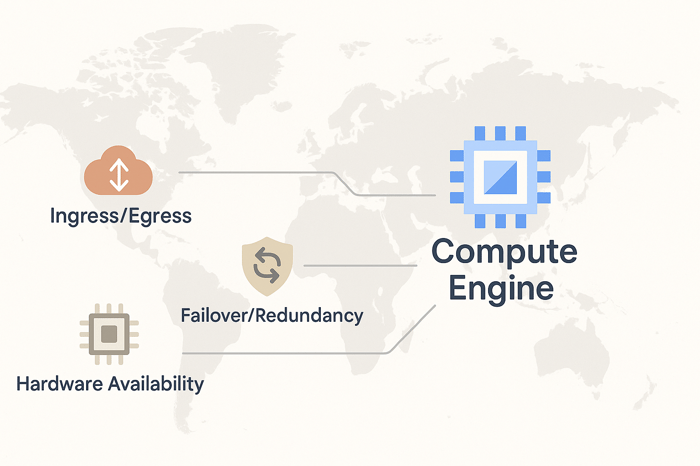
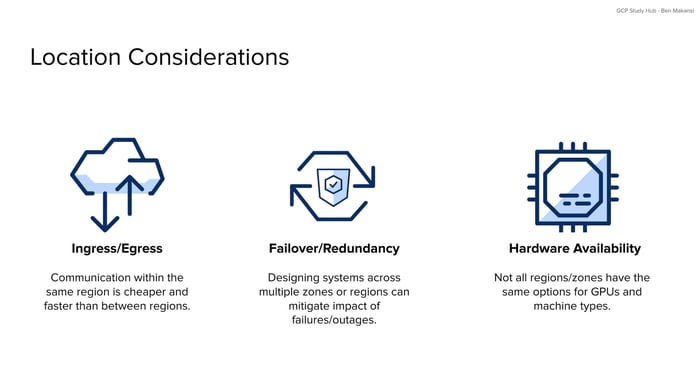
When choosing regions and zones for your GCE resources, three key factors influence placement decisions. These considerations often require balancing trade-offs, as optimizing for all three simultaneously may not be possible.
Ingress and Egress Optimization
Network communication patterns affect both performance and costs in GCP. Communication within the same region generally operates faster and costs less compared to cross-region traffic. When VM instances need to exchange data regularly, placing them in the same region can reduce latency and egress charges.
For applications with significant data transfer requirements, regional proximity becomes relevant for cost optimization. Cross-region data transfer incurs additional egress fees, while intra-region communication often carries reduced charges. This becomes particularly important for distributed applications, database clusters, or services that require frequent data synchronization between VM instances.
Failover and Redundancy Planning
Designing systems across multiple zones and regions provides protection against infrastructure failures. High availability architectures typically distribute Compute Engine resources across multiple zones within a region to protect against single-zone outages. This approach helps maintain service continuity when individual data centers experience issues.
Regional redundancy offers additional protection against regional failures. Deploying important GCE workloads across multiple regions provides a higher level of fault tolerance, though this approach requires consideration of data consistency, latency, and synchronization challenges.
The approach depends on matching your redundancy strategy to your availability requirements. Applications with strict uptime requirements benefit from multi-zone GCE deployments, while mission-critical services may warrant multi-region architectures despite the additional complexity and costs.
Hardware Availability Constraints
Not all regions and zones offer the same hardware options. Specialized Compute Engine resources like specific GPU types, high-memory instances, or newer generation machine types may only be available in certain locations. This hardware constraint can influence location decisions for workloads with specific performance requirements.
For machine learning workloads requiring NVIDIA GPUs, for example, you need to verify which regions and zones support the specific GPU models your VM instances require, as they're not available everywhere. Similarly, applications requiring substantial memory or high-performance local storage must consider hardware availability for those workloads when selecting VM locations.
These constraints often require checking resource availability during the planning phase, and mapping out your needs with the latest GCP documentation, as specialized hardware tends to be available in major regions and may not be offered in all geographic locations for Compute Engine deployments.
Balancing Competing Requirements
These three location considerations often create competing requirements that cannot all be optimized together, and as a cloud architect, you have to apply your judgment and understand the needs of the business or client in question in order to make a sound decision. An effective Compute Engine location strategy requires understanding these trade-offs and prioritizing based on your specific application needs.
 For example, achieving good ingress and egress costs by concentrating Compute Engine resources in a single region may conflict with redundancy requirements that call for geographic distribution. Similarly, as we discussed above, specific hardware requirements might only be available in regions that don't align with your preferred geographic distribution or cost optimization goals for VM instances.
For example, achieving good ingress and egress costs by concentrating Compute Engine resources in a single region may conflict with redundancy requirements that call for geographic distribution. Similarly, as we discussed above, specific hardware requirements might only be available in regions that don't align with your preferred geographic distribution or cost optimization goals for VM instances.
Successful architects evaluate these trade-offs carefully, and questions that require you to do so could show up on the Professional Cloud Architect exam.
Good cloud architects prioritize requirements based on business impact. They identify which factors are non-negotiable, and which can be compromised. This analysis helps determine whether and how performance, cost, availability, or hardware requirements should take precedence in Compute Engine location decisions.
The most practical approach involves clearly defining your requirements hierarchy before making Compute Engine location choices. Understanding whether your application prioritizes cost optimization, availability, specific performance characteristics, or particular hardware capabilities helps guide location decisions when trade-offs become necessary.
Intuition about how to do so often comes with time in the role, although evaluating case studies, like those you will be presented with on the Professional Cloud Architect exam, can help accelerate the development of that skill.
Conclusion
Understanding VM location strategy is important for success on the Professional Cloud Architect exam, as these decisions form part of well-architected GCP solutions. The permanent nature of Compute Engine location choices makes upfront planning worthwhile, requiring consideration of network costs, availability requirements, and hardware constraints.
Learning how to balance ingress and egress optimization, failover and redundancy planning, and hardware availability constraints demonstrates the strategic thinking required for cloud architecture roles. This knowledge proves useful for both exam success and real-world GCP implementations where Compute Engine location decisions can impact application performance, costs, and reliability.
By systematically evaluating these three key considerations and understanding their inherent trade-offs, architects can make informed Compute Engine location decisions that align with their specific requirements and constraints, ensuring reasonable instance placement for their particular use cases.