
To pass the GCP Professional Data Engineer exam, you have to know certain foundational concepts in Dataflow that define how data is represented and processed.
Let's go over them.
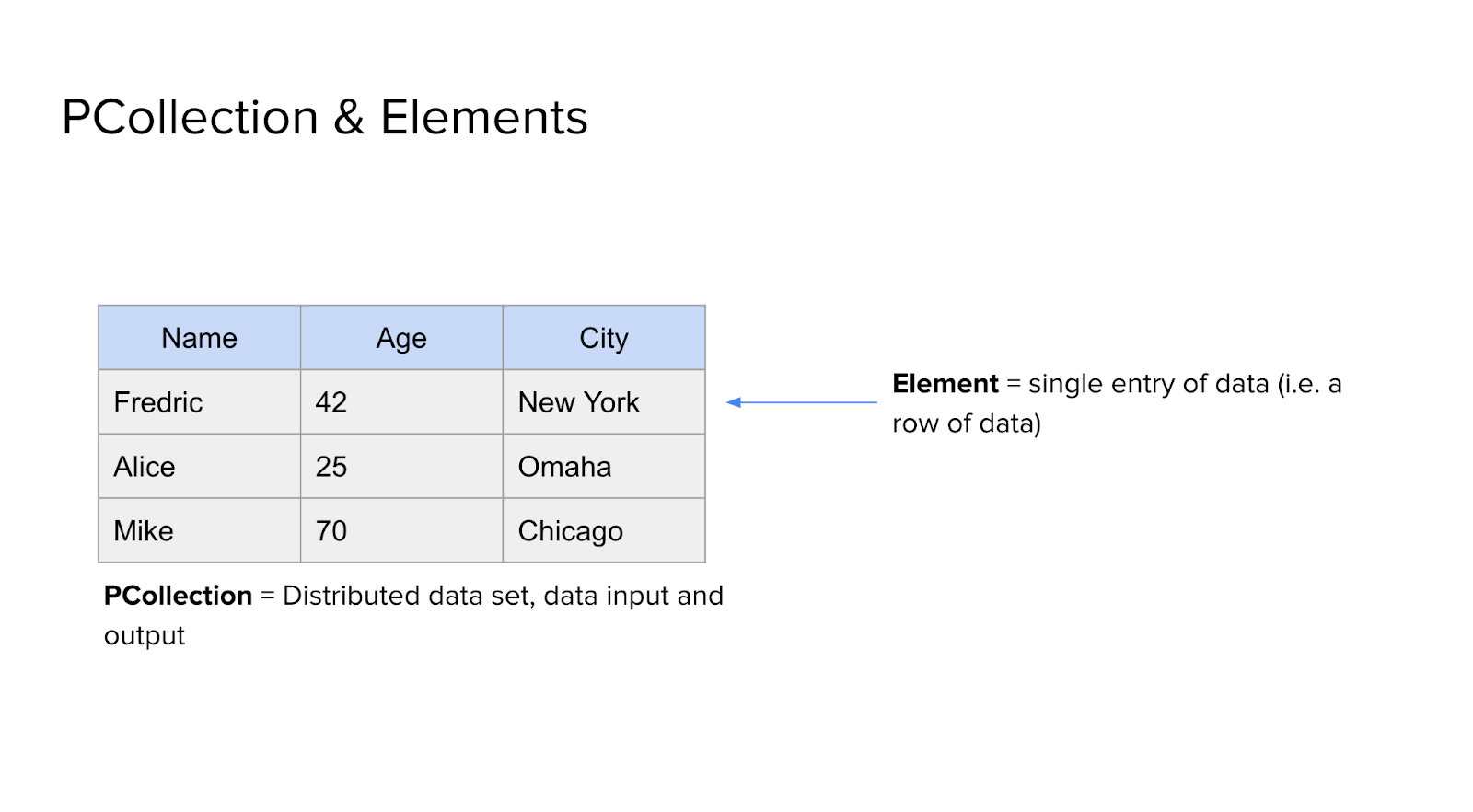
A PCollection is the basic data structure in Dataflow. It represents a collection of data that your pipeline will process. You can think of it as the input and output of your pipeline - it’s what flows through each step. A PCollection isn’t necessarily stored in one place; it’s distributed across the system to support parallel processing at scale.
Inside each PCollection are Elements, which are the individual pieces of data being processed. If you're working with user data, for example, one element might be a record like: name = Alice, age = 27, city = Seattle. Each element usually contains multiple fields, and the full set of elements forms the dataset.
Starting with these two concepts - PCollections and Elements - lays the groundwork for understanding how pipelines handle data. From here, more advanced topics like transforms, windowing, and triggers all build on this same model. Getting clear on these basics makes the rest of Dataflow much easier to grasp.
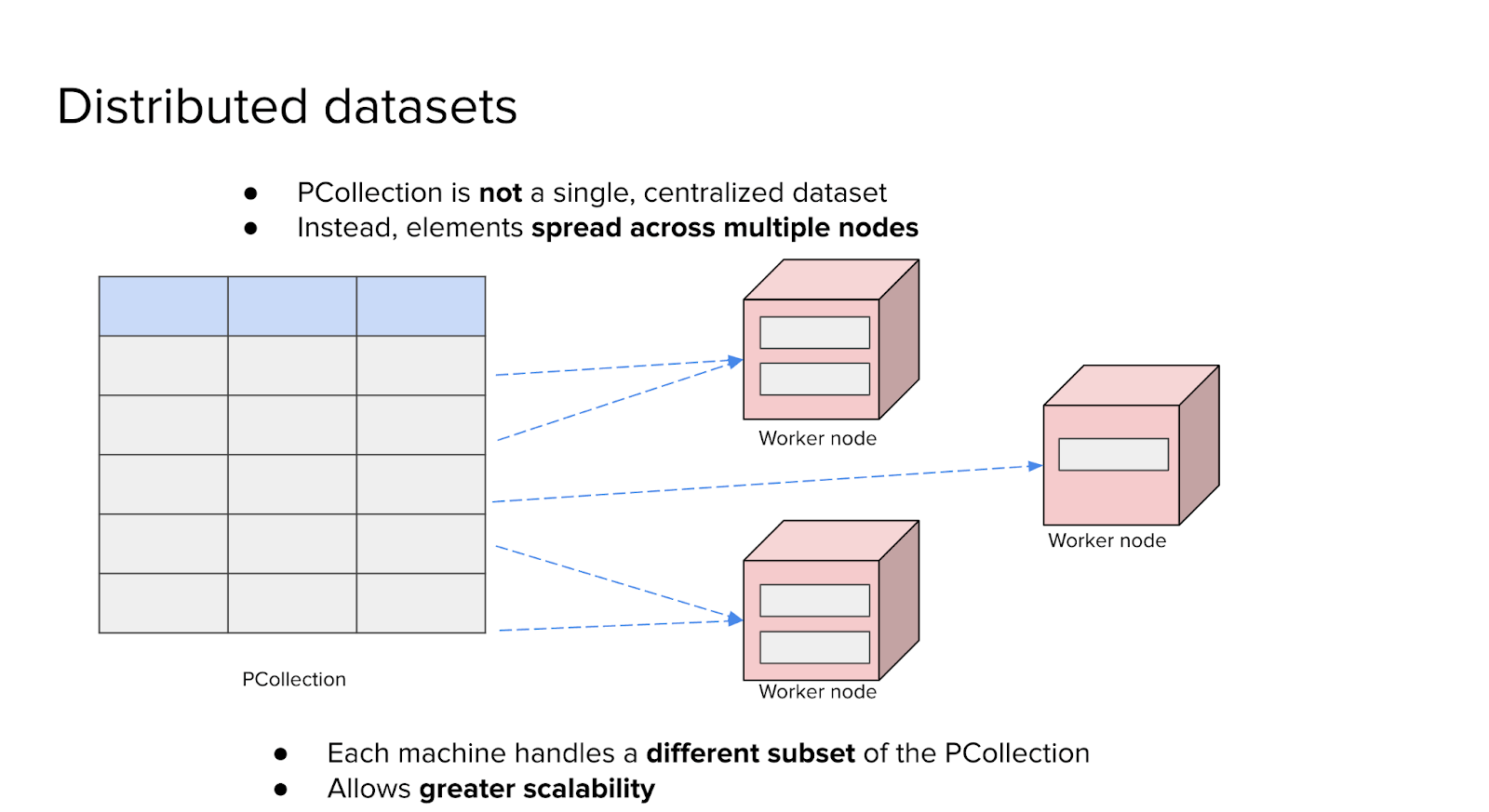
A common misconception when first learning Dataflow is to imagine a PCollection as a single, centralized dataset - something like a traditional database table. In reality, a PCollection is distributed by design. It exists not on a single machine but across many, enabling the kind of parallel processing that makes Dataflow scalable and efficient.
Consider a PCollection with just five elements. While we might visualize it as a small table, that table does not reside in one place. Instead, the elements are automatically divided and assigned to different worker nodes in the Dataflow cluster. Each node processes a subset of the data independently.
For example, one worker might handle the first two elements, another might process the next two, and a third could take the last. This distribution is key to how Dataflow achieves parallelism: multiple machines can work simultaneously on different parts of the dataset without needing to coordinate constantly with each other.
This distributed nature is what allows Dataflow to scale. As the size of the data increases, more workers can be added, and the system can continue to operate efficiently. The core idea to grasp is that a PCollection is not a monolithic structure - it is inherently partitioned and processed across many machines to support large-scale, high-throughput data pipelines.
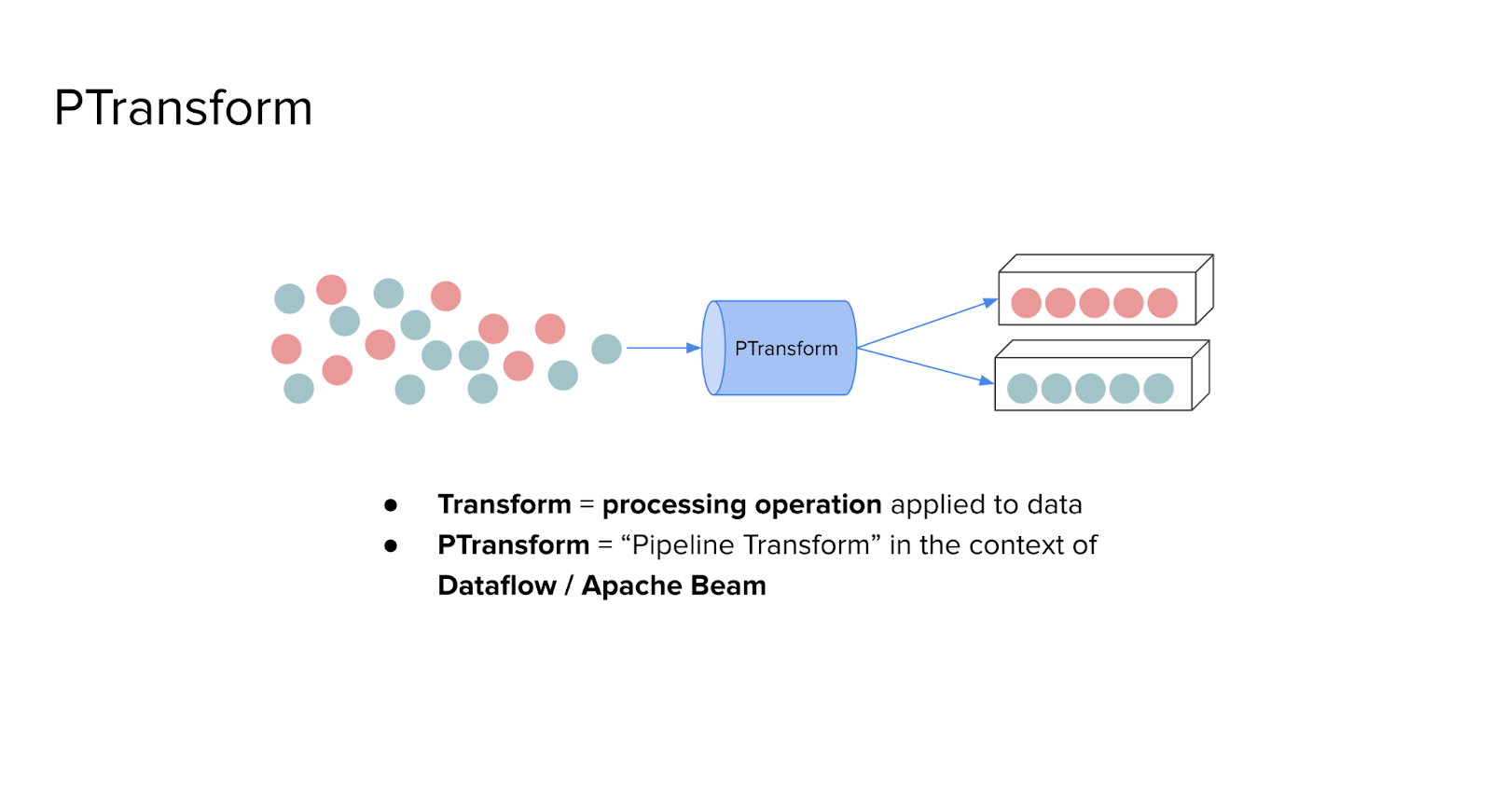
Once the structure of a PCollection is understood, the next essential concept is the PTransform. This term originates from Apache Beam, the programming model on which Dataflow is built, and it represents any operation that transforms data within a pipeline.
In Dataflow, a PTransform - short for Pipeline Transform - is the component responsible for processing data. It takes one or more input PCollections, applies a defined transformation, and produces one or more output PCollections. This could involve cleaning messy data, filtering unwanted records, grouping by a specific key, or performing aggregations.
Conceptually, you can imagine raw, unstructured data flowing into a PTransform. The transform applies logic or operations to the data, and the result is a new collection that is typically more structured, filtered, or ready for analysis.
There are many types of PTransforms available, each serving a distinct purpose - mapping values, filtering elements, grouping records, and more. In the context of the Professional Data Engineer exam, it’s important to recognize the common categories and understand how each one manipulates data within a pipeline. The upcoming sections will break these down in detail.
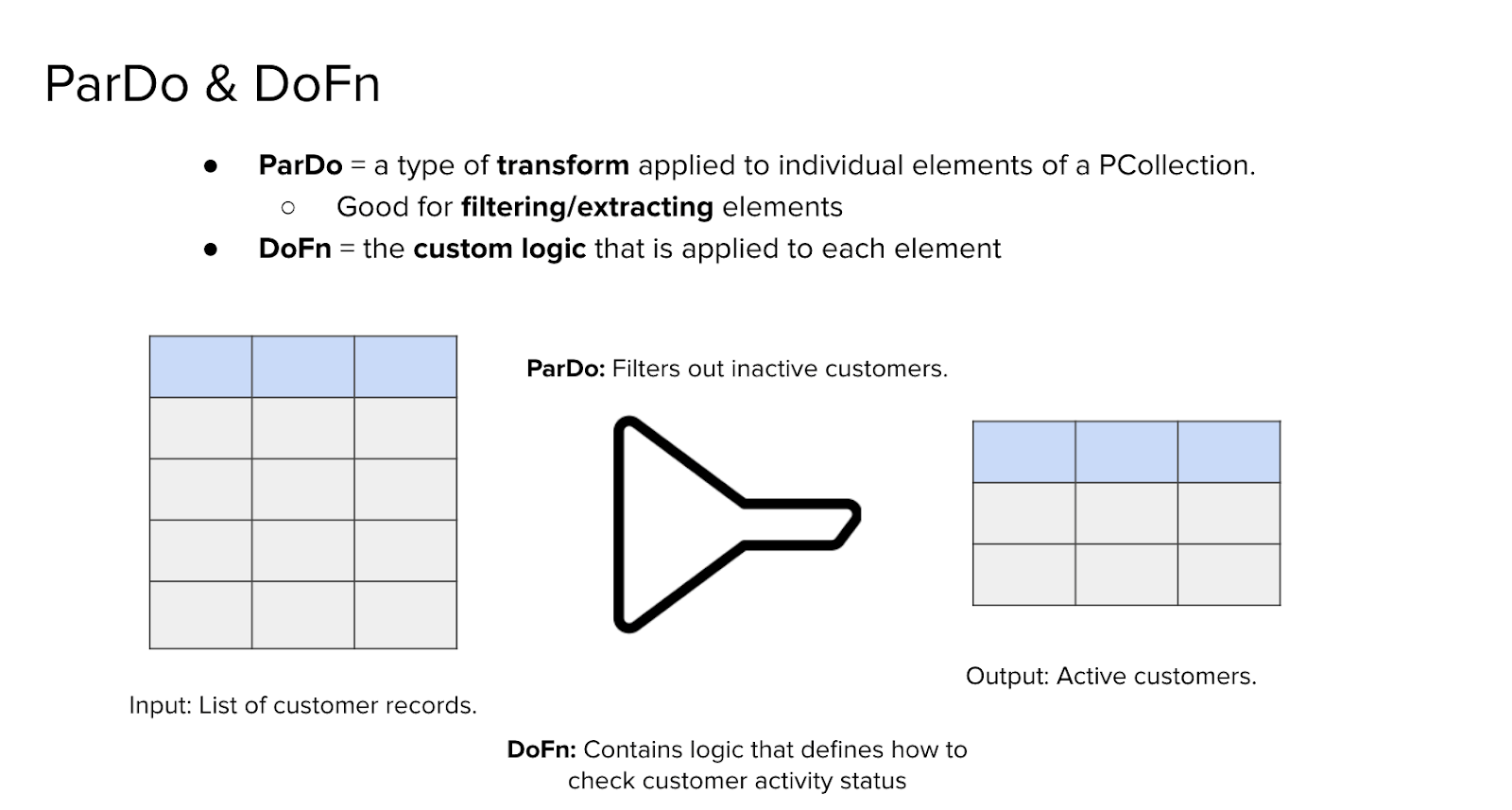
Among the various transformations available in Dataflow, ParDo is one of the most versatile and widely used. It enables element-wise processing of data within a PCollection, allowing for custom logic to be applied to each individual element. This makes it particularly useful for tasks such as filtering, validation, and restructuring of records.
At the core of a ParDo operation is the DoFn, short for “Do Function.” This is the user-defined function that specifies exactly what should happen to each element. Whether you're filtering out invalid records, enriching data with new fields, or transforming one input element into multiple outputs, the DoFn is where that logic lives.
To illustrate this, consider a PCollection containing customer records. Each element represents a different customer, and suppose the goal is to remove inactive customers. The ParDo transformation is applied to the entire PCollection, and the DoFn - written to check the “active” status - examines each element individually. Only elements that pass this condition are included in the output.
This transformation results in a new PCollection containing only active customers. The original dataset is preserved, but the pipeline now continues with a refined subset that meets the criteria defined in the DoFn.
Understanding how ParDo and DoFn interact is critical for building flexible and efficient pipelines. Together, they allow developers to inject custom logic at the element level, making it possible to shape and clean data in ways that simpler, fixed transforms cannot.
Two additional concepts that often appear in more advanced Dataflow pipelines are Side Input and Side Output. These mechanisms provide flexibility by allowing data to be enriched or redirected during processing.
A Side Input is supplemental data that is provided to a PTransform alongside the main PCollection. This is especially useful when the transform logic needs access to external references, such as configuration values, lookup tables, or thresholds. For instance, if each element in a dataset needs to be compared against a predefined list of valid values or scored using a reference table, that auxiliary data would be passed in as a side input. It allows each element to be processed in context, with additional information that isn’t part of the main dataset.
A Side Output, by contrast, enables a ParDo transform to emit multiple output PCollections. This is valuable when not all processed elements should follow the same path through the pipeline. For example, valid records may continue through the main processing logic, while invalid or flagged records are sent to a separate PCollection for error handling or audit logging. This separation allows downstream steps to treat these subsets differently without complicating the primary transformation logic.
Together, side inputs and side outputs expand the expressiveness of a Dataflow pipeline. They support use cases where external reference data is needed or where elements must be routed differently based on specific conditions, making pipelines more adaptable to complex business logic.

Another fundamental PTransform in Dataflow is GroupByKey, which plays a central role when organizing data by a shared attribute. It is especially useful in pipelines that involve grouping and aggregating records.
To understand how it works, consider a PCollection of key-value pairs. For example, you might have elements like ("apple", 3), ("banana", 4), ("apple", 5), and ("banana", 6). Each element has a key and an associated value. When GroupByKey is applied, all values associated with the same key are collected into a single group. The result is a new PCollection in which each key maps to an iterable of values - ("apple", [3, 5]) and ("banana", [4, 6]).
This operation is conceptually similar to the GROUP BY clause in SQL, but with an important difference. In SQL, grouping is typically paired with an aggregation function such as SUM, AVG, or COUNT, and the result is a reduced or summarized value for each group. In contrast, GroupByKey does not apply any aggregation by default. It simply organizes the values, leaving subsequent processing - such as summing or filtering those values - to additional steps in the pipeline.
This separation of grouping and aggregation allows for more flexibility. After grouping, developers can apply custom logic to each group, enabling use cases that go beyond standard SQL aggregations. For the Professional Data Engineer exam, it’s important to recognize that GroupByKey is often a preparatory step that enables later transformations rather than an aggregation mechanism in itself.
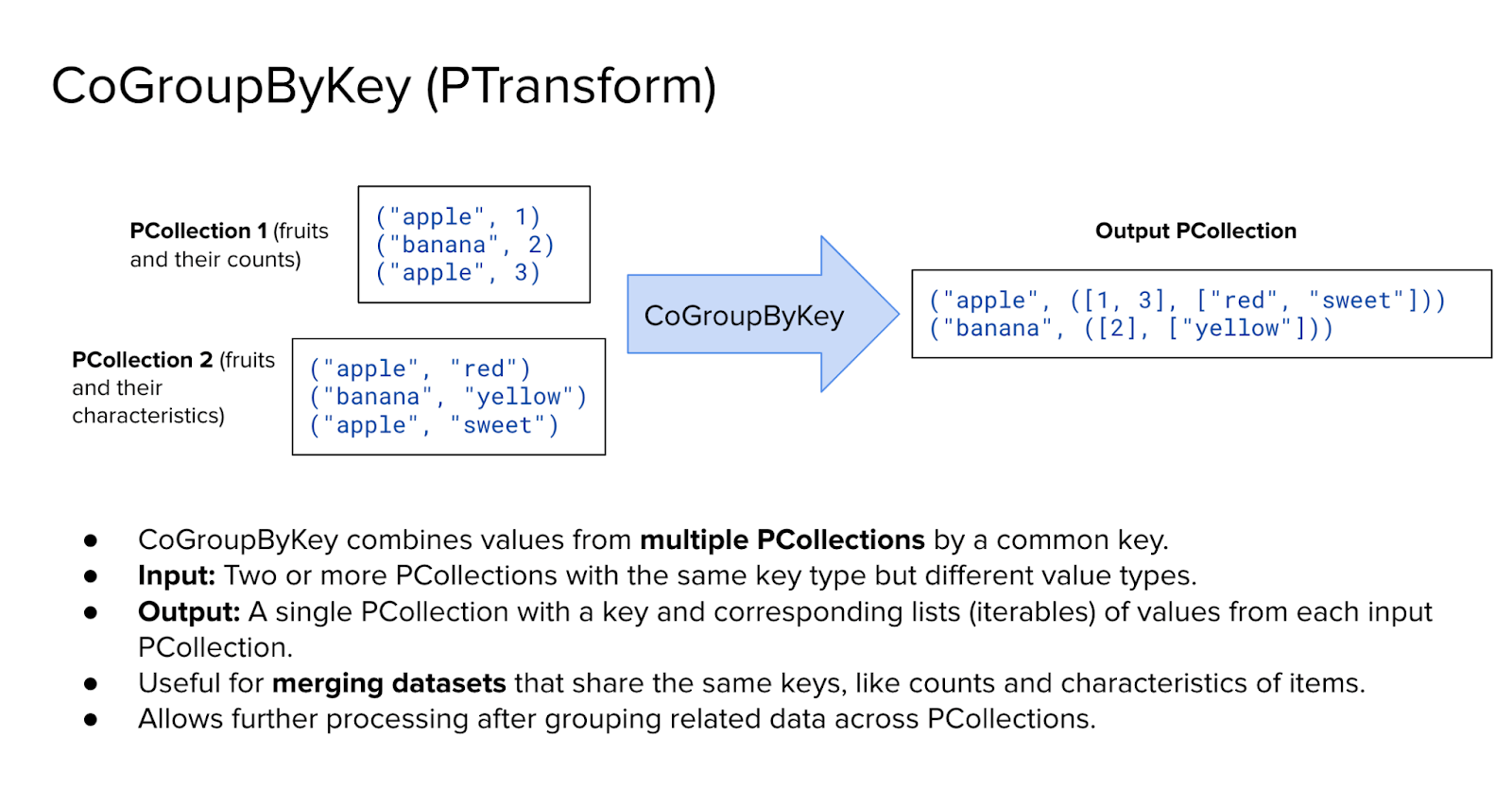
Building on the concept of grouping, CoGroupByKey is another important PTransform that enables joining multiple datasets by a shared key. It allows two or more PCollections to be combined based on common keys, similar to how a relational join works in SQL.
Imagine we have two separate PCollections. The first contains fruit names paired with their respective counts - such as ("apple", 3) or ("banana", 4). The second contains the same fruit names paired with characteristics - such as ("apple", "red") or ("banana", "soft"). Both PCollections use the fruit name as the key.
When CoGroupByKey is applied, it matches records from both PCollections that share the same key. The output is a new PCollection where each key maps to a pair of iterables: one containing all values from the first PCollection, and the other containing all values from the second. For instance, "apple" would be associated with two lists - one with all the counts, and one with all the characteristics.
This transformation is especially useful when merging datasets that represent different aspects of the same entities. Unlike GroupByKey, which operates on a single dataset, CoGroupByKey brings together multiple sources, making it well-suited for tasks such as enriching data, joining reference tables, or aligning parallel inputs.
After the datasets are combined, you can apply further processing to each group, just as you would with GroupByKey. The main difference is that now you have access to values from multiple sources, giving you a broader view of the data associated with each key.

Another useful transformation in Dataflow is Flatten, which allows you to merge multiple PCollections of the same type into a single unified PCollection. This is particularly helpful when your pipeline logic produces separate datasets that need to be recombined before further processing.
To illustrate, consider three PCollections:
The first contains records for "apple" and "banana"
The second includes "orange" and "pear"
The third contains only "grape"
Each of these PCollections follows the same schema - perhaps key-value pairs representing fruit names and their counts. When the Flatten transform is applied, these individual collections are combined into a single PCollection that contains all five elements: "apple", "banana", "orange", "pear", and "grape".
It’s important to note what Flatten does and does not do. It does not modify the content or structure of the elements. Instead, it simply concatenates all the input collections into one logical stream of data. All original data is preserved.
Flatten is most commonly used after operations like filtering or branching, where different subsets of data are processed independently and then need to be reunited. For the exam, it’s helpful to recognize situations where multiple PCollections must be merged and understand that Flatten is the appropriate tool for that task - as long as the data types are consistent across the inputs.
These core concepts - PCollections, Elements, PTransforms, ParDo, DoFn, Side Inputs, Side Outputs, GroupByKey, CoGroupByKey, and Flatten - form the foundation of working with Google Cloud Dataflow. A solid understanding of how Dataflow represents, transforms, and organizes data is essential for building scalable pipelines and for performing well on the Professional Data Engineer exam. If you found this breakdown helpful and want to dive deeper into exam-relevant topics with hands-on examples, consider enrolling in my full Professional Data Engineer course, designed to help you master GCP services and pass the exam with confidence.

